Connaitre et maintenir la qualité de ses données

L’équipe Craft a organisé en novembre 2021 un atelier sur la qualité des données.
Cet atelier s’appuyait sur la restitution du travail d’Elouan Girot, stagiaire en licence MIASHS, sur la « qualité des données » dans Craft. Il a permis de définir et d’identifier des indicateurs génériques de qualité pour les Domaines d’Intérêt, de calculer avec des outils statistiques (R) ces indicateurs et de programmer un outil de visualisation et de suivi en temps réel de ces indicateurs.
Pour ce travail, Elouan s’est appuyé sur les indicateurs de la thèse de Ion George Todoran sur la dynamique de la qualité de l’information et des données d’un système d’information complexe (Etude Performance et fiabilité. Télécom Bretagne ; Université de Rennes1,
2014). Les indicateurs sont :
- Qualité « système » : temps d’accès, sécurité, disponibilité de la plateforme …
- Qualité de « structuration » : présence d’une Chaine de valeur, présence d’infobulles, traduction des champs…
- Qualité des « données et valeurs » : les champs sont-ils remplis, comportent-ils des données aberrantes, niveau de confiance …
Nous nous sommes intéressés aux 2 derniers types d’indicateurs. En allant dans le détail, nous pouvons préciser :
- Données et valeurs :
- Complétude : indicateur qui mesure la quantité/le pourcentage de valeurs manquantes pour chaque champ
- Précision : indicateur qui mesure le degré de précision que l’on observe dans la saisie des données. Il vérifie notamment la présence éventuelle de valeurs aberrantes
- Obsolescence / fraicheur des données : indicateur qui s’intéresse à la distribution des entités selon le champ « date de dernière modification »
- Structuration :
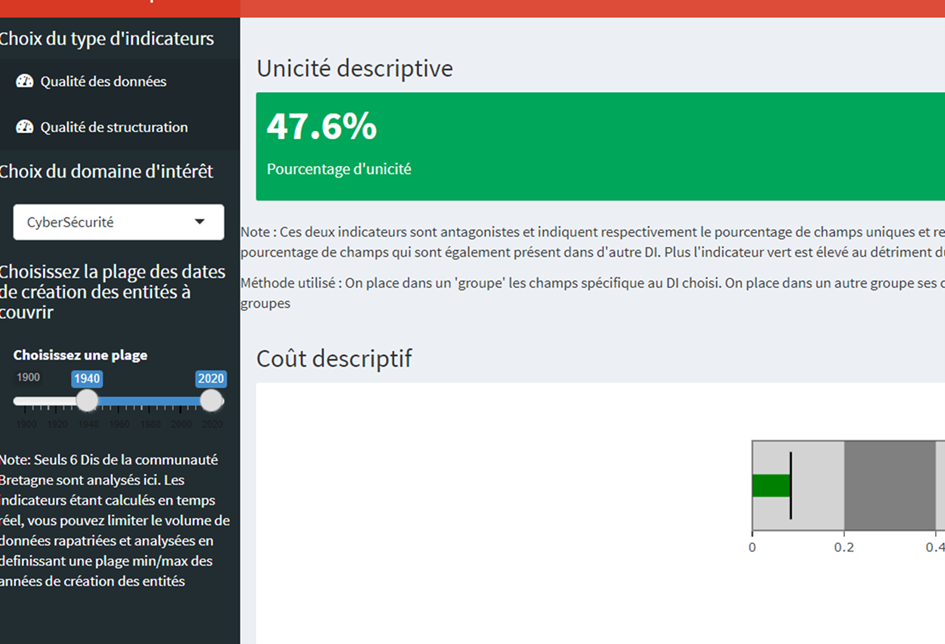
- Coût descriptif : c’est le rapport entre le nombre de champs d’un DI, et le nombre d’entités de ce DI. Un faible nombre de champs pour un grand nombre d’entités se traduit par un coût descriptif faible. L’entrée d’un nouvel acteur se fait rapidement et favorise la dynamique du DI. Inversement, un grand nombre de champs pour peu d’entités indique un coût descriptif fort, il faut structurer énormément pour un parc d’acteurs réduit. Il faudra donc se poser la question de la rationalité et de l’exploitation de ces données (faut-il passer plus de temps à renseigner ou à exploiter/valoriser ?)
- Unicité descriptive : indicateur qui s’intéresse au nombre de champs uniques (non présent dans d’autres DI) par rapport au nombre total de champs de ce DI. Plus ce pourcentage est élevé, meilleure est la qualité des données. Inversement une unicité descriptive faible inique que les champs du DI sont déjà présents ailleurs (dans d’autres DI ou dans les Champs Communs). Il faudra donc s’interroger sur l’intérêt de « recréer » ces champs dans le DI alors qu’ils existent ailleurs.
- Ambiguïté potentielle / taux de liberté descriptive : indicateur qui s’intéresse au nombre de champs de texte libre par rapport au nombre total de champs du DI. Ainsi, les champs de texte libre permettent une grande liberté d’expression et donc de capter les spécificités et subtilités des compétences des acteurs. Mais cela peut complexifier les actions de classifications et de segmentation. Et donc de valorisation.
L’intérêt de cette démarche est bien de nous questionner sur les champs et les types d’informations que l’on collecte dans nos Domaines d’Intérêt et d’identifier des pistes d’amélioration.
Plus d’information sur les indicateurs de suivi de son Domaine d’Intérêt : Evaluer la dynamique de son Domaine d’Intérêt
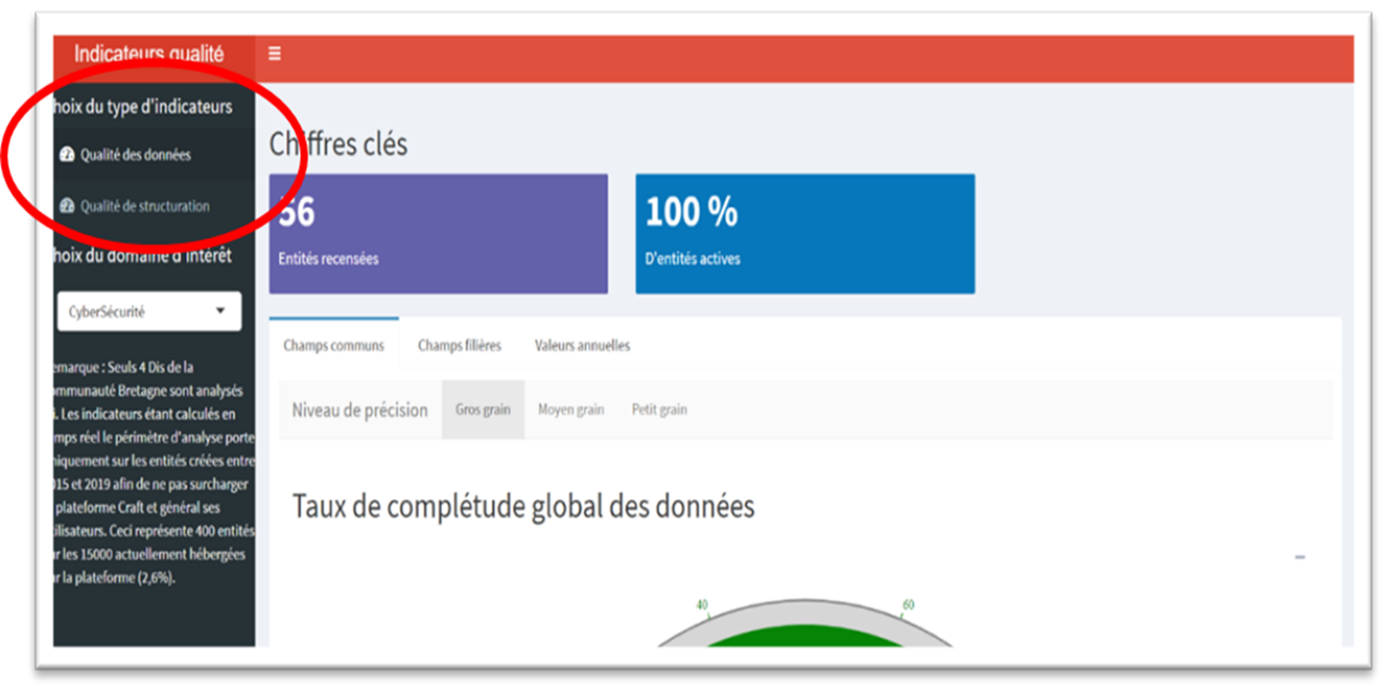
Le calcul de ces indicateurs doit être réalisé à différentes échelles pour être pertinent. Nous avons donc distingué :
- gros grain : calcul à l’échelle du DI : notamment au niveau de l’ensemble des Champs Communs
- grain moyen : calcul par bloc de données
- grain fin : calcul d’indicateurs au niveau de chaque champs.

A partir de cette première analyse, Elouan a pu calculer ces indicateurs pour quelques DI et proposer un tableau de bord interactif grâce à une API de Craft et une interface de visualisation sous Shiny :
Ce tableau de bord est encore au stade expérimental et nous cherchons des partenaires susceptibles de tester et travailler avec nous sur ce sujet. N’hésitez pas à revenir vers nous pour prolonger cette façon originale de voyager dans vos données !